

Cet article fait partie du dossier : Ingénierie de la donnée territoriale
Voir les 4 actualités liées à ce dossier
Contexte
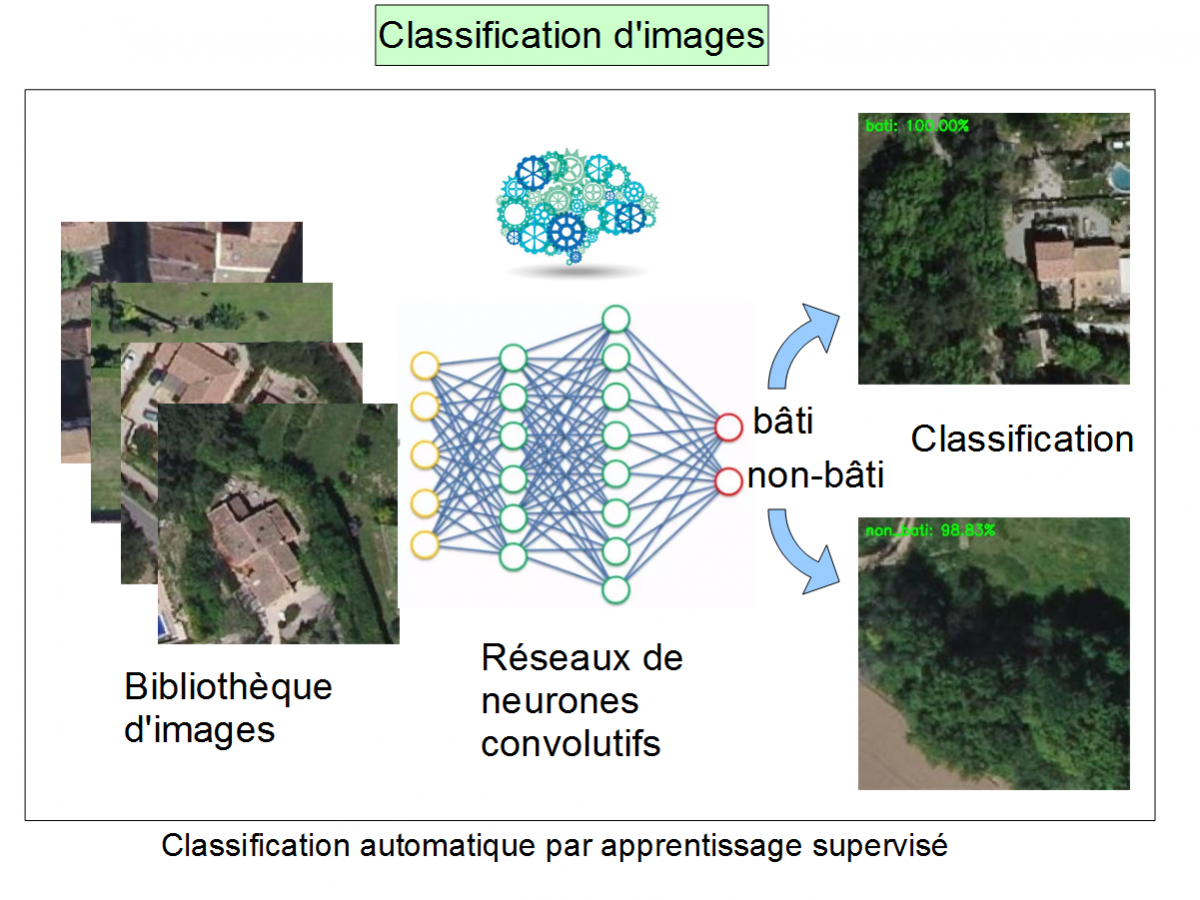
L’objectif de cet exercice est de présenter un cas concret d’utilisation des techniques d’intelligence artificielle dans une application métier. Pour cela, nous avons choisi le thème de la classification d’image, en présentant la détection de bâtiments sur des images aériennes.
Tous les éléments produits dans le cadre de cette étude (images labellisées pour l'entraînement, code, modèles ) ont été déposés sur le compte Github du Cerema à l’adresse suivante : https://github.com/CEREMA/dtermed.ML_bati_non-bati
Pré-requis
Dans notre cas, nous avons été amenés à procéder à l’installation de différents éléments (étape non développée dans cet article) :
- python 3.6
- keras, tensorflow
- QGIS (pour la génération des lots d'entraînement)
- création d'une bibliothèque d'images pour entraîner le modèle
Ne disposant pas de catalogue d'images directement disponible sur internet (il en existe différents pour identifier chats/chiens, modes de transports...), nous avons réalisé notre propre catalogue d'image grâce à la fonctionnalité Atlas de QGIS à partir de données suivantes: une ortho-photographie + la couche "bâtiments" de la BDTopo.
- réalisation d'un dallage de 50m x 50m
- croisement géographique avec les bâtiments BDTopo pour catégoriser les dalles en 2 classes:
-->des dalles "bati"

--> et des dalles "non-bati"

La requête que nous avons utilisée est très simple (peut-être trop) car elle se contente de dire si un bâti (ou une portion de ce dernier) est présent sur le carreau. En réalité, pour avoir un lot de meilleure qualité, un petit nettoyage serait à réaliser afin de supprimer:
- les détections abusives/manquantes (dues à un écart d'actualité entre l'ortho-photo et la couche de bâtiments)
- les dalles où des bâtiments sont réellement présents au sol mais, soit invisibles sur la photo depuis le ciel (à cause du couvert végétal), soit représentant une trop petite surface (d'où la possibilité de mettre des seuils minimums lors de la catégorisation établie précédemment).
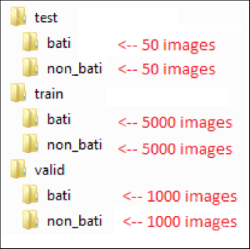
Nous avons établi une bibliothèque comprenant au total 12100 images: 10000 pour entraîner le modèle , 2000 pour le valider, et 100 pour les tests.
Préparation du modèle
Les différents paramètres du modèle sont définis dans un script python. On y retrouve par exemple:
- une fonction d'augmentation d'image : des actions de rotation, décalage, effet miroir, étirement ou zoom permettent d'augmenter significativement le nombre d'images en entrée (sans toucher à la bibliothèque) et d'éliminer certains biais engendrés par l'orientation ou la position de certains éléments au sein de l'image
- la définition des classes recherchées, aussi appelée labels ou étiquettes (bati/non-bati)
- l'emplacement des données d'entrée
- l'enchaînement des blocs de fonctions de notre réseau de neurones
Exemple d'enchaînement :
model.add(Conv2D(32,(3,3), input_shape=(img_width, img_height, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(32,(3,3), input_shape=(img_width, img_height, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64,(3,3), input_shape=(img_width, img_height, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.summary()
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
Ce modèle est constitué de 5 blocs, à savoir :
- trois blocs de convolution-pooling qui servent à interpréter les images et en extraire les features, soit les motifs caractéristiques, plus ou moins abstraits à mesure que l'on va profondément dans le réseau.
- deux couches entièrement connectées, dont la première sert de couche intermédiaire avec la dernière qui sert à la classification (avec un neurone de sortie pour sortie binaire)
La courbe obtenue à l'issue de l'entraînement donne des renseignements sur la pertinence du réseau entraîné, et peut mettre en évidence certains biais comme un sur-apprentissage du réseau de neurones (lorsque le réseau apprend par cœur et n'arrive pas à généraliser ses connaissances à de nouvelles images qu'on lui soumet).
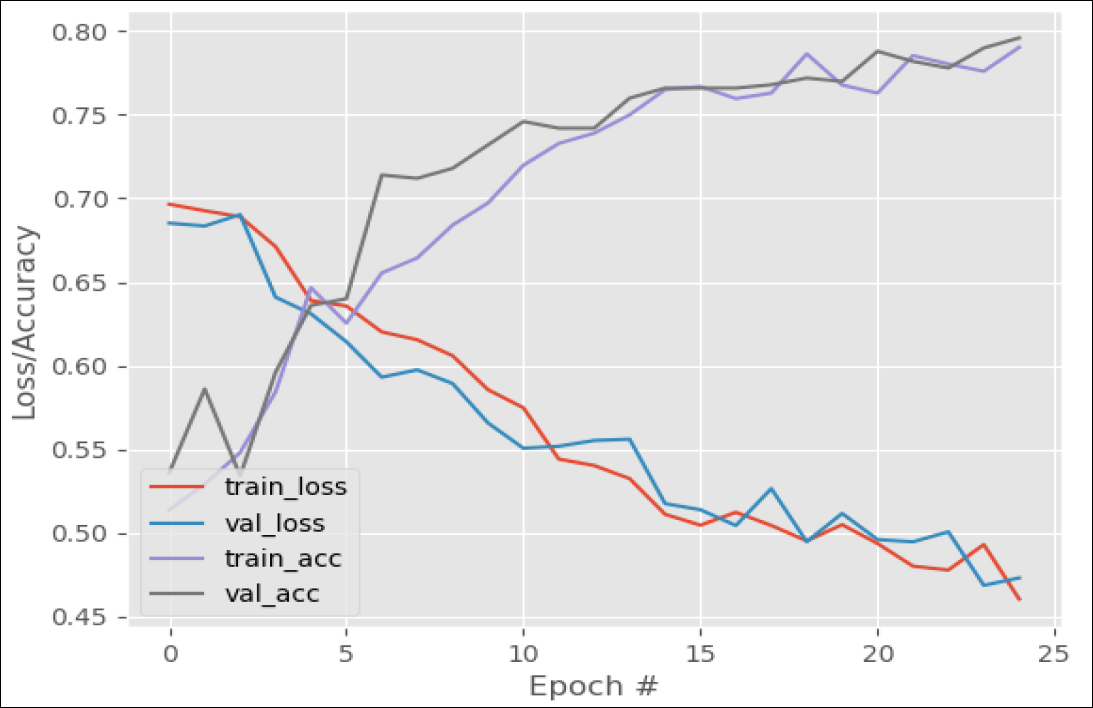
La visualisation des courbes de précision et de coût, pour les lots d'entraînement et de validation, permet de voir la performance du modèle et le nombre d'epochs à compter duquel le modèle atteint ses meilleures performances.
En général, à la suite de cela, on modifie le nombre de blocs, le type de fonctions à utiliser, la profondeur du réseau de neurones, de façon à obtenir un modèle plus performant. L'atteinte d'un "meilleur" modèle, à savoir un qui ne sur-apprend pas, et qui réponde aussi bien aux données d'entraînement que de validation, se fait par une succession d'itérations et d'essais à la suite desquels on modifie les hyper-paramètres du réseau de neurones.
Cela prend généralement du temps et s'apparente davantage à un art qu'à une science exacte.
Test du modèle
Le test du modèle est effectué sur 100 nouvelles images, n'ayant servi ni à l'entraînement, ni à la validation, mais qui ont tout de même été catégorisées lors de la création du jeu de données.
Le résultat est rendu sous la forme d'images annotées avec la prédiction d'appartenance à l'une ou l'autre des 2 classes attendues: bâti / non-bâti

A ce stade, il convient de vérifier la pertinence de la prédiction en fonction de la catégorisation initiale.
Exemple de prédictions correctes :

...et quelques erreurs évidentes:

La présence d'erreurs de ce type peut permettre de mettre en évidence certains défauts:
- jeu de données pas totalement propre (modèle entraîné avec des images mal classées au départ)
- mauvais paramétrage du modèle
Nous allons voir comment y remédier.
Importance du paramétrage du modèle :
En utilisant les mêmes jeux de données de départ, la définition du modèle aura une incidence sur le résultat produit. L'amélioration de la précision se fera donc par itérations successives, comme dit précédemment (petite partie "bidouille").
Attention: le nombre de "paramètres" à déterminer lors des calculs en dépendra, ce qui aura une une incidence non négligeable sur les temps de calculs (pouvant aller de quelques minutes à plusieurs heures)
Voici les résultats produits par 3 codes différents :

Pour aller plus loin...
La qualité et la précision du résultat dépendent de certains facteurs:
- avoir un jeu de données le plus propre possible, sous peine de donner de mauvaises informations lors de l'apprentissage et générer des erreurs de classification en sortie (garbage in – garbage out)
--> solutions :
- avoir le meilleur couplage possible entre image aérienne et bâti (choisir les bons millésimes, d'un point de vue chronologique)
- supprimer les images propices à mauvaise interprétation en intervenant sur des critères tels que la surface de bâti présente sur le carreau, sa localisation relative sur ce dernier...
- veiller à obtenir des taux de précision cohérents (normalement quasi-identiques) sur le jeu d'entraînement et le jeu de validation, afin de ne pas rester en situation de sur-apprentissage ou de sous-apprentissage
--> solutions :
- jouer avec des paramètres architecturaux comme la profondeur du réseau de neurones, le nombre de filtres, le nombre de neurones dans les couches entièrement connectées,
- utiliser des techniques de régularisation dont la plus fameuse, le dropout, qui consiste à éteindre aléatoirement certains neurones
- choisir le bon optimiseur (Adam étant un bon choix par défaut)
Questions fréquentes
Quel matériel pour faire de la classification d'images?
L'apprentissage du modèle est une opération qui requiert de grosses capacités de calculs, mais cela peut néanmoins être réalisé sur un ordinateur portable (moyennant quelques heures d'attente des résultats).
Pour se familiariser avec le machine learning, il existe également des solutions en ligne (par exemple les notebooks Jupyter), permettant d'utiliser les outils installés sur le cloud et sans aucune configuration sur poste.
Exemple: Colaboratory (https://colab.research.google.com/notebooks/welcome.ipynb)
Quelle est la taille minimale des jeux de données?
Il est tout à fait possible de pouvoir entraîner un modèle de classification d'images avec peu d'images au départ (par exemple: 2000 images pour l'entraînement + 800 pour la validation). La production d'un propre jeu de données est une opération qui peut s'avérer coûteuse, et des fonctions d'augmentation d'images permettent de le rendre plus robuste.
En revanche, il est important d'avoir un jeu de données bien proportionné (en classes et en apprentissage / validation).
Où trouver des jeux de données d'images/ modèles pré-entraînés?
De nombreux jeux de données (datasets) sont disponibles en téléchargement sur internet, dans plusieurs catégories: banques d'images (MNIST, CIFAR, Pascal VOC, ImageNET, MS Coco...), mais aussi des données vidéos, textuelles ou faciales...
On trouve également sur internet (par exemple https://modelzoo.co/) des modèles pré-entraînés (l'entraînement étant une opération qui peut être longue) et prêts à l'emploi pour certains types de jeux de données.
Dans le dossier Ingénierie de la donnée territoriale